Problems faced while fitting data to a model
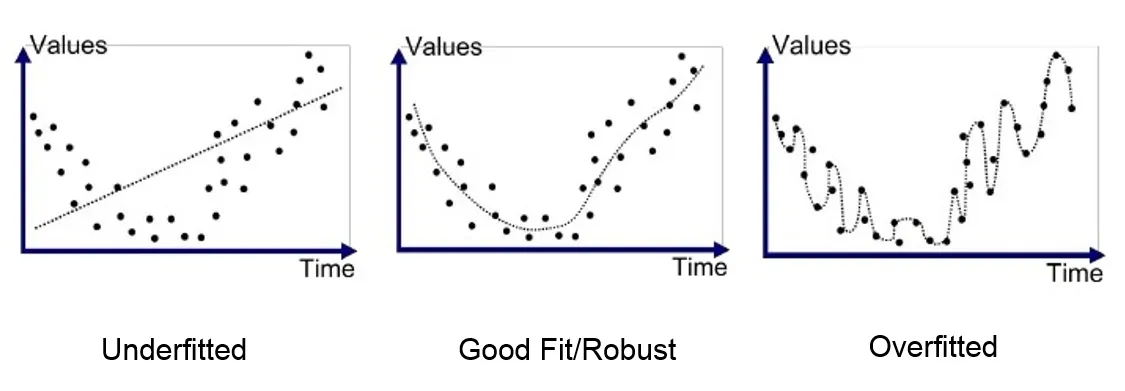
Overfitting-
Here is a reason why you do not want your machine learning model to get 100% accuracy on training data that is…Overfitting!!!
A model overfits when it simply memorizes the data, e.g. a curve that fit through every training data. If the overfitted model is tested on the training data the model will give 0 training error. So, to test the model generalization ability, the model should be tested on unseen test cases.
When a model overfits to the training dataset it becomes extraordinarily good at working with the training dataset but will potentially fail to work any other dataset that is even slightly different.
For example, if your model is trained to detect an apple but it is overfitting to the training data of red apples then it will not be able to detect a green apple or a black and white image of a red apple or a slightly out of shape apple. It will forever only be able to detect red apples that are exactly similar to the training dataset you provided any slight difference would throw it off.
One could say there is no intelligence part involved in an overfit model. So, when building a machine learning model it is important to make sure you do not overfit your model to your training data. A solution to avoid overfitting is using a linear algorithm if we have linear data or using the parameters like the maximal depth if we are using decision trees.
In contrast to this the other problem faced while trying to fit training data to a model is:
Underfitting-
A statistical model or a machine learning algorithm is said to have underfitting when it cannot capture the underlying trend of the data. Underfitting destroys the accuracy of our machine learning model. Its occurrence simply means that our model or the algorithm does not fit the data well enough. It usually happens when we have less data to build an accurate model and also when we try to build a linear model with a non-linear data. In such cases the rules of the machine learning model are too easy and flexible to be applied on such minimal data and therefore the model will probably make a lot of wrong predictions. Underfitting can be avoided by using more data and also reducing the features by feature selection.
Gain Access to Expert View — Subscribe to DDI Intel
